
Imagine you’re writing an essay or a report, and you need to include some information that you’re not an expert on. Instead of just guessing or making things up, what if you had a super smart assistant that could quickly look up relevant information for you from reliable sources? That’s kind of what Retrieval-Augmented Generation (RAG) is all about.
Basically, RAG is a way for those fancy generative AI models, like the ones that can write essays or code for you, to enhance their capabilities by retrieving and using information from external sources. It’s like having a built-in research assistant!
Retrieval-Augmented Generation (RAG) is an AI workflow that enhances the capabilities of generative AI models by incorporating information retrieval from external sources. It is a two-step process that involves retrieving relevant information from a corpus or knowledge base and then using that retrieved information to augment the generation process of the AI model.
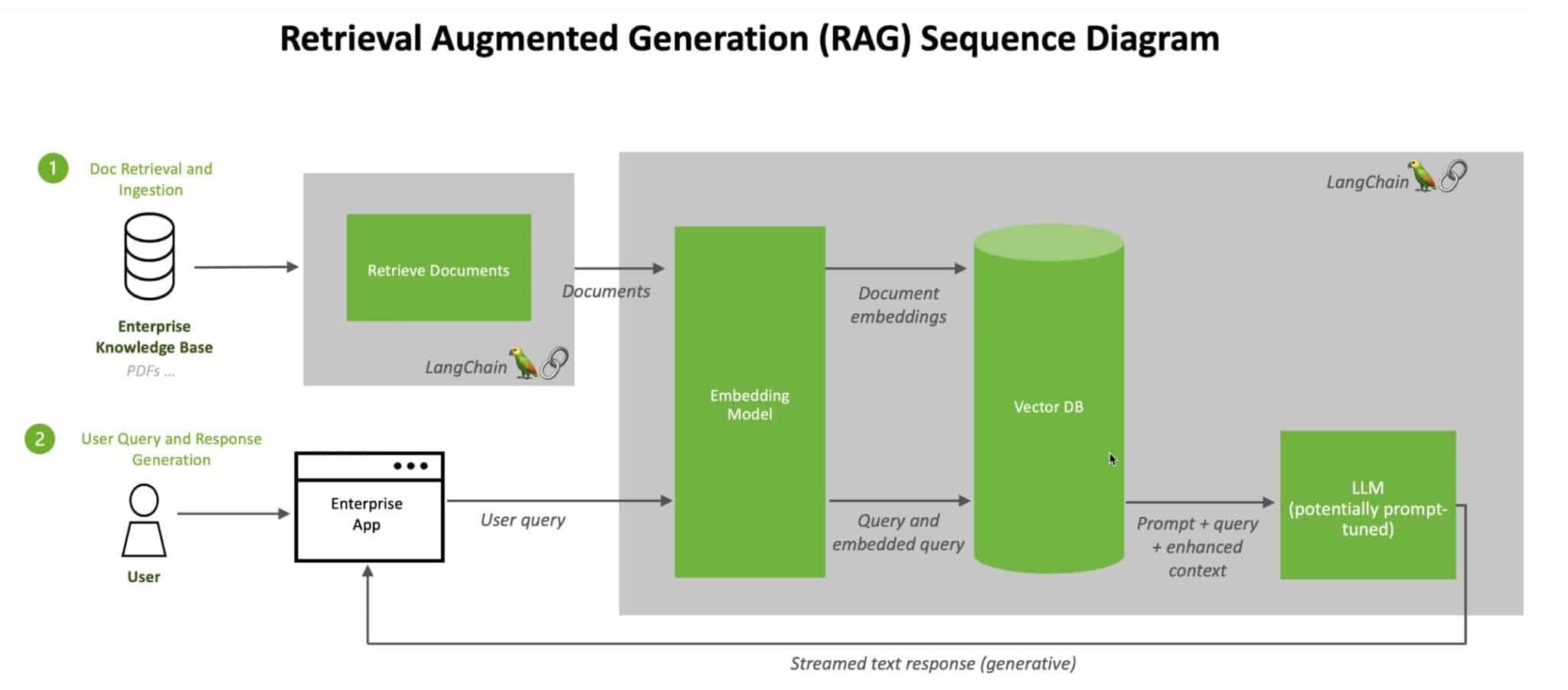
In essence, retrieval-augmented generation works by harmoniously integrating retrieval and generation components to produce accurate, contextually relevant, and informative text outputs, thereby enhancing the capabilities of large language models in various applications.
Retrieval-Augmented Generation (RAG) is like giving your AI a superpower boost by combining its brain with external knowledge sources. Let’s break down the benefits of RAG:
RAG taps into foundation models (FMs) that are like the encyclopedias of the AI world, they are API-accessible Large Language Models (LLMs) trained on a wide range of generalized and unlabeled data. This means your AI can pull in a wealth of diverse and up-to-date information to give you the most relevant and comprehensive responses.
By blending external knowledge with its generative powers, retrieval-augmented generation serves up responses that are not just accurate but also rooted in real-world data. Say goodbye to errors and hello to high-quality outputs!
With RAG, your AI becomes a real-time information concierge, delivering timely and trustworthy responses that keep users satisfied. Engaging with a system that’s always in the know? Users are more likely to trust and interact with a system that delivers current and reliable information. That’s a win-win for everyone.
RAG reduces the computational and financial costs associated with continuously training models on new data. By leveraging existing knowledge sources, organizations can save time and resources while still maintaining the accuracy and effectiveness of their AI systems.
Beyond just chatbots, RAG can be your go-to for various tasks like summarizing text, answering questions, or sparking dialogues. It’s like having a versatile AI sidekick that’s always ready to lend a hand. This versatility makes RAG a valuable tool for a wide range of AI applications.
By fusing the raw power of foundation models with the wealth of knowledge from external sources, RAG gives these generative AI beasts a serious upgrade. We’re talking enhanced reliability, efficiency, and the flexibility to tackle any use case you throw at them.
RAG isn’t just some fancy buzzword – it’s the real deal when it comes to keeping those advanced language models grounded in rock-solid, up-to-date facts without breaking the bank on constant retraining. And here’s the kicker – we at SoftmaxAI are the AI experts you need on your side.
Our AI service will have your intelligent applications running circles around the competition. Need a bulletproof cloud setup? We’ll build you an infrastructure in the cloud that’s tougher than a tank. Data pipelines giving you a headache? Leave it to our data engineering to whip your data into intelligent shape. The bottom line is, that if you’re serious about staying ahead of the curve with cutting-edge AI and cloud solutions, you need to get SoftmaxAI in your corner ASAP. Don’t keep playing catch-up – hit us up and let’s get to work.